Content
Publications
1. M. Umbert, J. Bonada, M. Goto, T. Nakano, J. Sundberg, "Expression Control in Singing Voice Synthesis: Features, Approaches, Evaluation, and Challenges" IEEE Signal Processing Magazine, 2015.
2. M. Umbert, J. Bonada, M. Blaauw, "Systematic Database Creation for Expressive Singing Voice Synthesis Control", 8th ISCA Speech Synthesis Workshop (SSW8), Barcelona, Spain, September 2013.
3. M. Umbert, J. Bonada, M. Blaauw, "Generating Singing Voice Expression Contours Based on Unit Selection", Stockholm Music Acoustics Conference (SMAC), Stockholm, Sweden, July 2013.
Audio Samples
Reference
M. Umbert, J. Bonada, M. Goto, T. Nakano, J. Sundberg, Expression Control in Singing Voice Synthesis: Features, Approaches, Evaluation, and Challenges, IEEE Signal Processing Magazine, 2015. [In Press]
Audio content
1. Audio samples which are refered in the original article.
2. Classification of Expression Control Methods in Singing Voice Synthesis.
3. Gathered singing voice synthesis performances with different expression control approaches:
where both URLs from the original publication and audio are provided if available.
* in case the audio link is not provided in the refered article, audios are published with the author's permission.
| Description | Clara Rockmore’s theremin performance of Vocalise |
| Sound | Original source |
| Samples |
| Description | Expression analysis of a singing voice recording sample |
| Sound | MTG Studio Recording |
| Samples |
Classification of Expression Control Methods in Singing Voice Synthesis
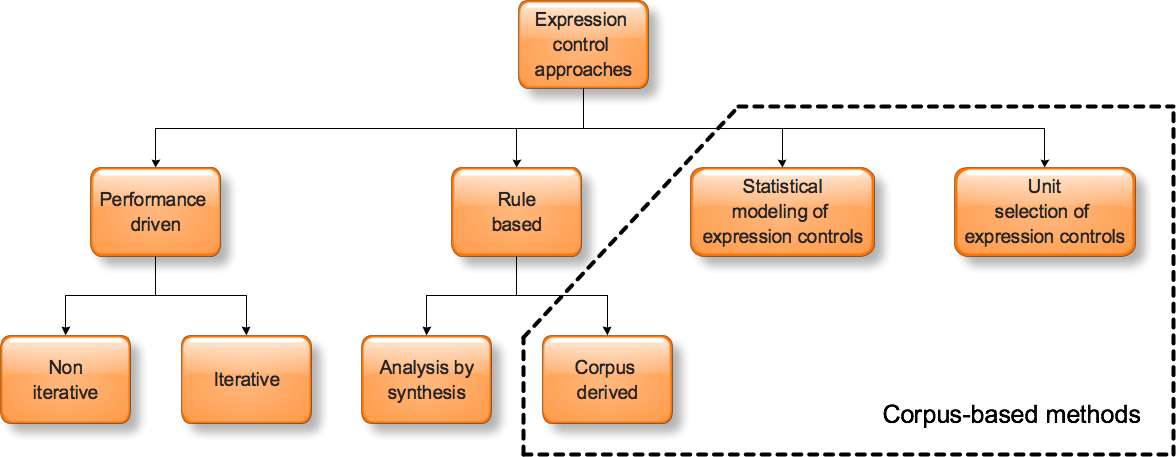
Singing voice synthesis performances with different expression control approaches
1. Performance-driven
2. Rule-Based
3. Statistical Modeling
4. Unit Selection
Performance-driven
| Title | High Quality Singing Synthesis using the Selection-based Synthesis Scheme |
| Type | Non-iterative |
| Publication | |
| Sound | |
| Synthesized audio |
| Title | Performance-driven control for sample-based singing voice synthesis |
| Type | Non-iterative |
| Publication | |
| Sound | |
| Reference audio | |
| Synthesized audio |
| Title | Speech-to-singing synthesis: converting speaking voices to singing voices by controlling acoustic features unique to singing voices |
| Type | Non-iterative |
| Publication | |
| Sound | |
| Reference audio | |
| Synthesized audio | |
| Reference audio | |
| Synthesized audio |
| Title | VocaListener: A Singing-to-Singing Synthesis System Based on Iterative Parameter Estimation |
| Type | Iterative |
| Publication | |
| Sound | |
| Reference audio | |
| Synthesized audio |
| Title | VocaListener2: A Singing Synthesis System Able to Mimic a User's Singing in Terms of Voice Timbre Changes As Well As Pitch and Dynamics |
| Type | Iterative |
| Publication | |
| Sound | |
| Reference audio | |
| Synthesized audio |
Rule-based
| Title | The KTH synthesis of singing |
| Type | KTH rules |
| Publication | |
| Sound | Original audio links and description in the reference |
| Ex 3: Different pitch change timing | |
| Ex 13: Synthesized tenor voice | |
| Ex 16: Synthesized boy soprano |
| Title | Expressive Performance Model for a Singing Voice Synthesizer |
| Type | KTH-rules with Vocaloid |
| Publication | |
| Sound | * |
| Audio: dry | |
| Audio: anger | |
| Audio: fear | |
| Audio: happy | |
| Audio: sad | |
| Audio: tender |
| Title | Voice Processing and Synthesis by Performance Sampling and Spectral Models |
| Type | Empirically based |
| Publication | |
| Sound | * |
| Song 1 (Excerpt 1): Female | |
| Song 1 (Excerpt 2): Male | |
| Song 2 (Excerpt 1): Female 1 | |
| Song 2 (Excerpt 1): Female 2 | |
| Song 2 (Excerpt 2): Male 1 |
Statistical Modeling
| Title | An HMM-based Singing Voice Synthesis System |
| Type | HMM-based |
| Publication | |
| Sound | Not available: check Sinsy as a later system improvement |
| Title | Recent Development of the HMM-based Singing Voice Synthesis System - Sinsy |
| Type | HMM-based |
| Publication | |
| Sound | |
| Audio: dry | |
| Audio: anger |
| Title | A singing style modeling system for singing voice synthesizers |
| Type | HMM-based |
| Publication | |
| Sound | Not available |
Unit Selection
| Title | Generating Singing Voice Expression Contours Based on Unit Selection |
| Type | Unit selection |
| Publication | |
| Sound | |
| Song 1: default synthesis | |
| Song 1: expressive synthesis | |
| Song 2: default synthesis | |
| Song 2: expressive synthesis |
Reference
M. Umbert, J. Bonada, M. Blaauw, Generating Singing Voice Expression Contours Based on Unit Selection , Stockholm Music Acoustics Conference (SMAC), Stockholm, Sweden, July 2013. [PDF] [poster]
Audio Samples
| Song 1: Synthesis configurations | Audios |
| Default | |
| Manually Tuned | |
| Unit selection based framework |
| Song 2: Synthesis configurations | Audios |
| Default | |
| Manually Tuned | |
| Unit selection based framework |
| Song 3: Synthesis configurations | Audios |
| Default | |
| Manually Tuned | |
| Unit selection based framework |
