This is the material we used in the presentation at the SMAC poster session this summer. You can find a video showing the differences on expression performance between the default configuration and our framework set up. The poster pdf file is also available.
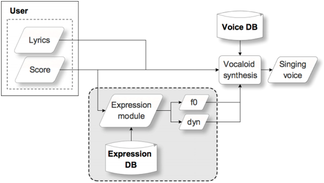 A common problem of many current singing voice synthesizers is that obtaining a natural-sounding and expressive performance requires a lot of manual user input. This thus becomes a time-consuming and difficult task. In this paper we introduce a unit selection-based approach for the generation of expression parameters that control the synthesizer. Given the notes of a target score, the system is able to automatically generate pitch and dynamics contours. These are derived from a database of singer recordings containing expressive excerpts. In our experiments the database contained a small set of songs belonging to a single singer and style. The basic length of units is set to three consecutive notes or silences, representing a local expression context. To generate the contours, first an optimal sequence of overlapping units is selected according to a minimum cost criteria. Then, these are time scaled and pitch shifted to match the target score. Finally, the overlapping, transformed units are crossfaded to produce the output contours. In the transformation process, special care is taken with respect to the attacks and releases of notes. A parametric model of vibratos is used to allow transformation without affecting vibrato properties such as rate, depth or underlying baseline pitch. The results of a perceptual evaluation show that the proposed approach is comparable to parameters that are manually tuned by expert users and outperforms a baseline system based on heuristic rules.
M. Umbert, J. Bonada, M. Blaauw, Generating Singing Voice Expression Contours Based on Unit Selection, Stockholm Music Acoustics Conference (SMAC), Stockholm, Sweden, July 2013. |
Martí UmbertThis will be the place for news, event updates, and other interesting stuff found on the web Archives
September 2019
Categories
All

|
 RSS Feed
RSS Feed
